
Introducción
¡Hola de nuevo, comunidad! 👋
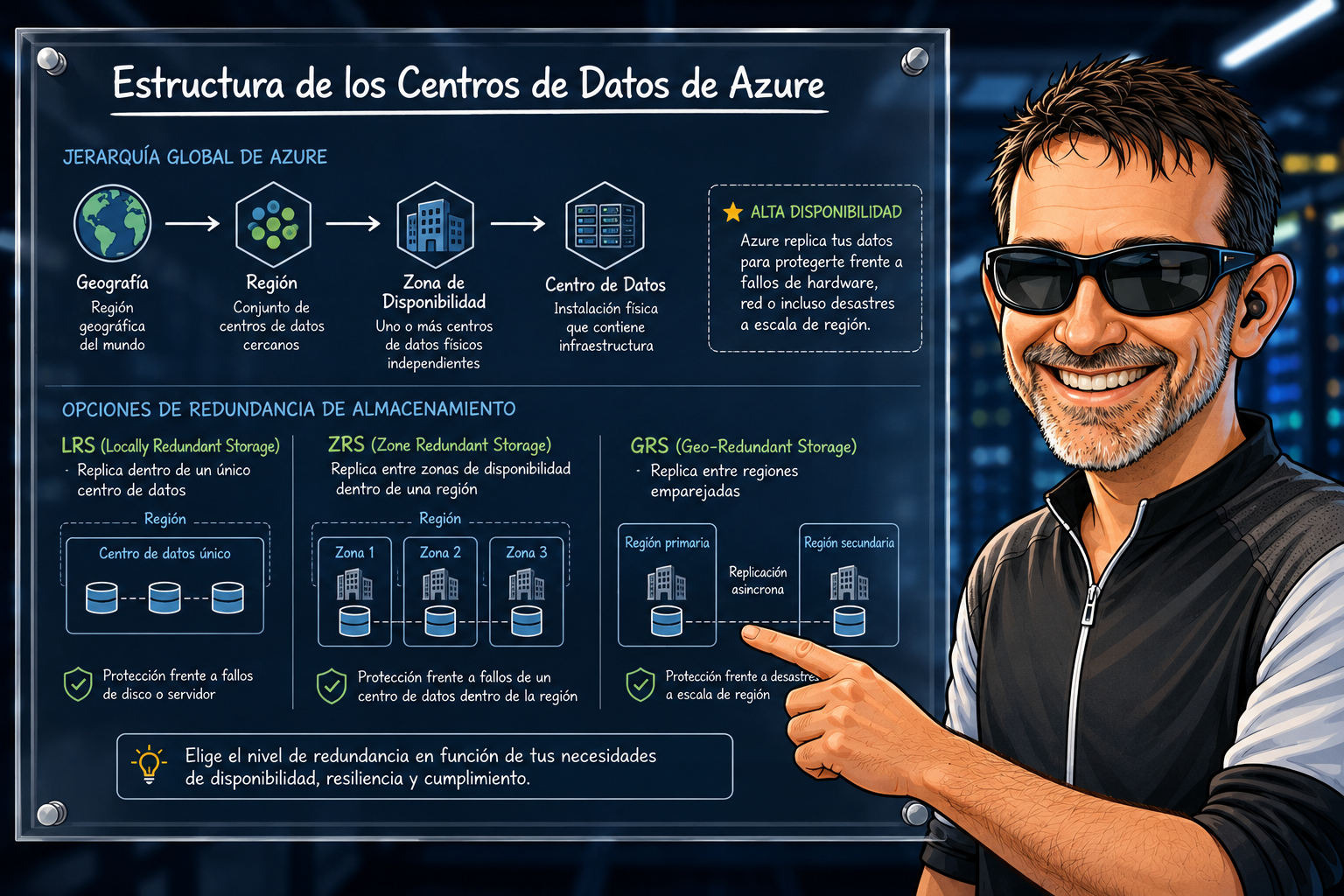
En el post anterior sentamos las bases viendo cómo se organiza Azure en geografías, regiones, zonas de disponibilidad y datacenters. Hoy toca aplicar ese conocimiento: vamos a hablar de replicación en Azure Storage y de cómo elegir entre LRS, ZRS, GRS, RA-GRS, GZRS y RA-GZRS sin tirar de intuición.
Por tanto, hoy toca la parte aplicada: ¿Cómo aprovechamos esa estructura para proteger nuestros datos? Veremos las 6 opciones de replicación que ofrece Azure Storage, cuándo usar cada una, cuánto cuesta el «seguro» y, lo más importante, qué pasa de verdad cuando algo falla.
Sin más rodeos, vamos allá!
Primero: ¿Qué entendemos por «replicación»?
En Azure Storage, replicación significa: «cuántas copias de tus datos se mantienen y dónde se guardan». Esto se configura a nivel de cuenta de almacenamiento y aplica a todos los servicios que contiene (Blobs, Files, Queues, Tables, Disks).
Y aquí va el primer mito a borrar de nuestra mente: la replicación no equivale a un Backup. Es decir, si eliminas un blob, este blob queda eliminado de todas las copias. La replicación te protege de fallos de infraestructura, no de errores humanos ni de ransomware. Para esas cosas existen otras mecanismos como es el caso de «Soft Delete», «Versioning» o el mismísimo «Azure Backup».
Aclarado esto, sigamos…
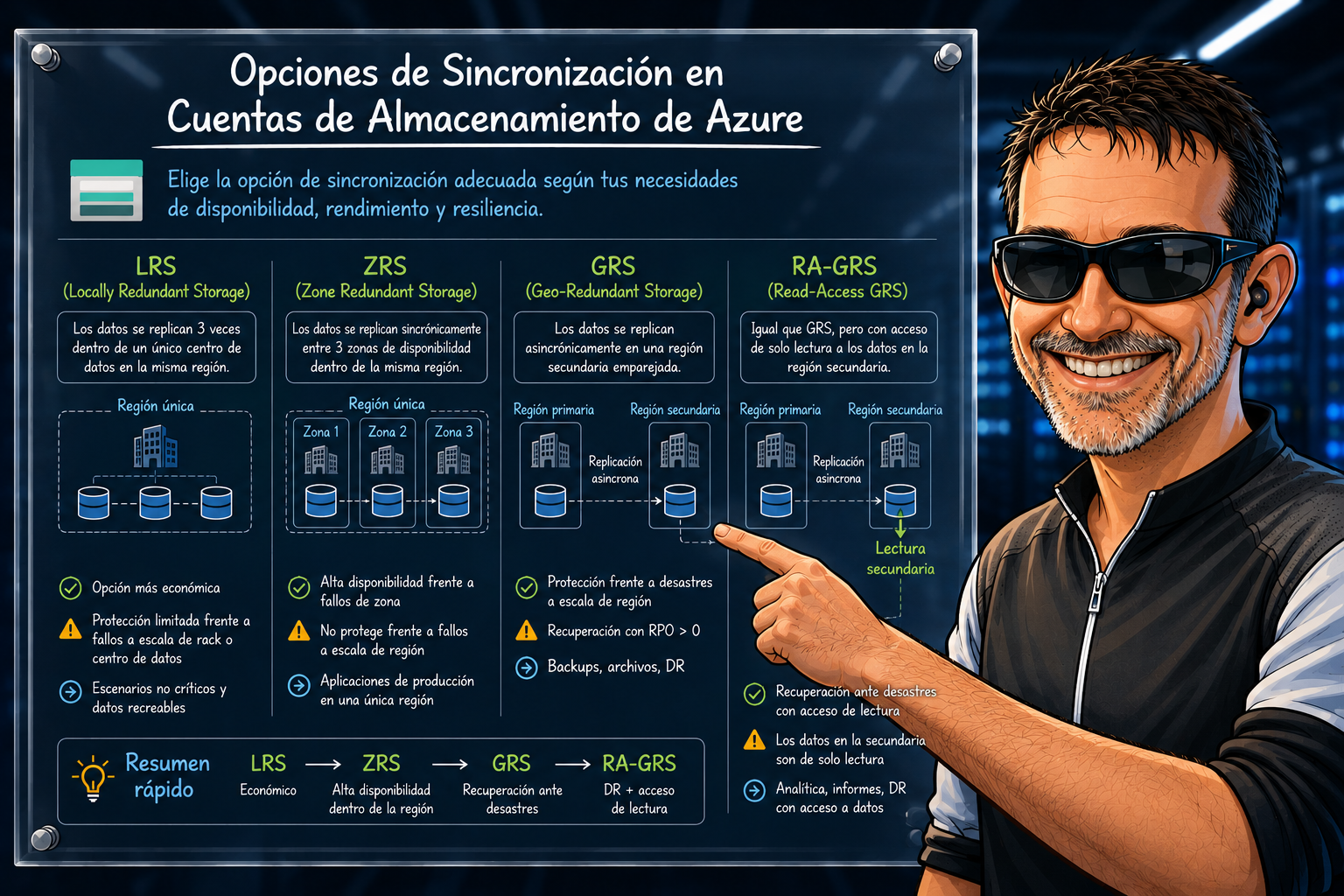
Las 6 opciones de un vistazo
| Sigla | Nombre | Copias | Dónde |
| LRS | Locally Redundant Storage | 3 | 1 datacenter |
| ZRS | Zone Redundant Storage | 3 | 3 zonas en la misma región |
| GRS | Geo Redundant Storage | 6 | 3 en primaria (LRS) + 3 en la región emparejada |
| RA-GRS | Read-Access GRS | 6 | Igual que GRS pero con lectura en secundaria |
| GZRS | Geo Zone Redundant Storage | 6 | 3 zonas en la región primaria + 3 en la región emparejada |
| RA-GZRS | Read-Access GZRS | 6 | Igual que GZRS pero con lectura en secundaria |
Ahora toca desmenuzar cada una de ellas.
1. LRS – Locally Redundant Storage
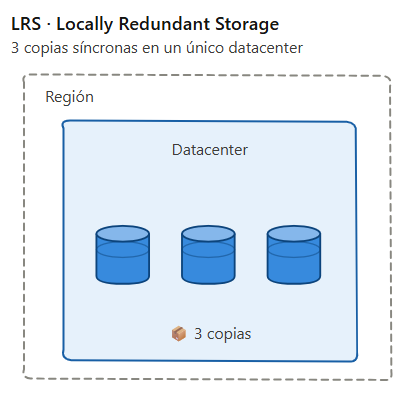
Objetivo: Mantener 3 copias síncronas de tus datos dentro de un único centro de datos de la región.
Ejemplos de sobre qué protege:
- Fallo de disco.
- Fallo de servidor.
- Fallo de rack
Ejemplos de que no nos protege:
- Incendio o inundación en el datacenter
- Caída de zona
- Caída de región
Es el tipo de replicación síncrona más barata de todas.
Cuando usarlo:
- Entornos de desarrollo y test.
- Datos que se pueden reconstruir fácilmente (cachés, logs efímeros, datos intermedios de procesamiento, etc).
- Workloads donde te obligan por cumplimiento a no salir de una zona física concreta.
2. ZRS – Zone Redundant Storage
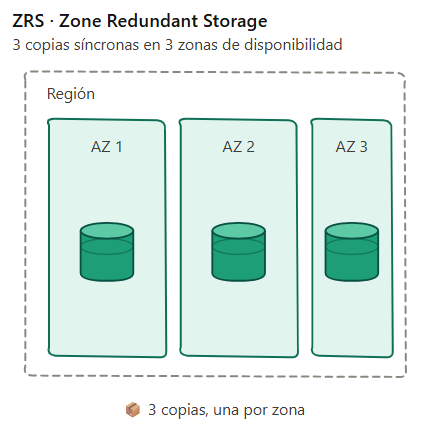
Objetivo: Replica síncronamente tus datos entre 3 zonas de disponibilidad distintas dentro de la misma región.
Ejemplos de sobre qué protege:
- Todo lo LRS
- Caída completa de una zona de disponibilidad.
Ejemplos de que no nos protege:
- Caída de región completa (terremoto, fibra cortada, etc.)
En cuanto al coste, es un 25% más caro que LRS.
Cuando usarlo:
- Producción: sin requisitos estrictos de DR cross-region.
- Aplicaciones que ya están desplegadas como zone-redundant (VMs en varias AZs, App Service con zone redundancy, etc.).
- Por defecto, es mi recomendación para casi cualquier carga productiva, siempre y cuando la región soporte AZs (Zonas de disponibilidad).
ZRS es el «sweet spot» para la mayoría de casos productivos. Te da resiliencia real a un coste razonable, y la escritura sigue siendo síncrona (no pierdes consistencia).
3. GRS – Geo Redundant Storage
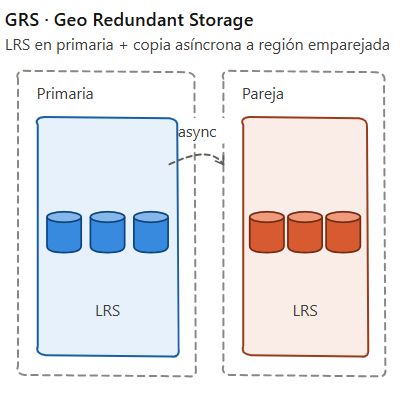
Objetivo: LRS en la región primaria más replicación asíncrona a la región emparejada, donde también se guarda como LRS
Ejemplos de sobre qué protege:
- Todo lo LRS
- Desastre regional (la región entera se cae)
Ejemplos de que no nos protege:
- Caída de zona en la región primaria (recuerda: dentro de cada región es LRS, no ZRS)
- Lectura desde la secundaria mientras la primaria funciona (para eso está RA-GRS), es decir, los datos en la secundaria no se pueden leer a no ser que la primeria haya caído.
En cuanto al coste, aproximadamente el doble de LRS.
Cuando usarlo:
- Cargas con requisitos de «DR cross-region» pero donde tu región primaria no tiene AZs.
- Backups y archivos donde lo que importa es sobrevivir a un desastre regional.
- Cumplimiento con exigencia de geo-redundancia.
4. RA-GRS – Read-Access Geo Redundant Storage
Objetivo: lo mismo que GRS, pero expone un endpoint adicional de solo lectura en la región secundaria. Tus aplicaciones pueden leer desde la secundaria en cualquier momento, no solo durante un failover.
El endpoint adicional tiene el sufijo «-secondary», por ejemplo:
https://micuenta.blob.core.windows.net ← primaria (R/W)
https://micuenta-secondary.blob.core.windows.net ← secundaria (Read Only)
Cuando usarlo:
- Aplicaciones donde quieres distribuir carga de lectura geográficamente.
- Reporting o analítica que puede tolerar datos ligeramente desfasados.
- Pruebas de DR: puedes verificar que tus datos están llegando a la secundaria sin tener que hacer failover real.
Un punto a tener en cuenta es el tráfico «egress»: leer desde el endpoint secundario en otra región genera tráfico inter-región que se factura (0,09 €/GB en Europa). Con tráfico pesado, esto se nota en la factura. Monitorízalo.
5. GZRS – Geo Zone Redundant Storage
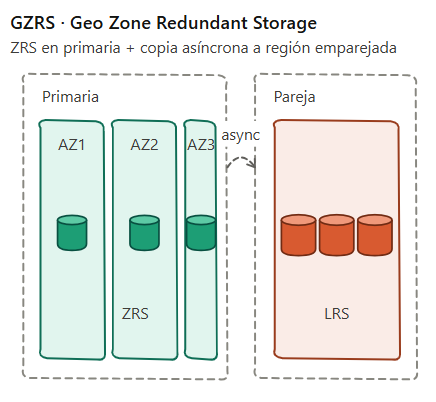
Objetivo: ZRS en la región primaria (3 AZs) + Replicación asíncrona a la región emparejada (donde se guarda como LRS).
Ejemplos de sobre qué protege:
- Fallo de disco/servidor/rack
- Caída de zona en la primaria
- Caída de región completa
Es la opción más completa que ofrece Azure Storage.
En cuanto al coste, el más caro, aproximadamente 2,3 X LRS.
Cuando usarlo:
- Sistemas críticos de producción que requieren máxima disponibilidad y DR.
- Tier-0 de negocio: ERPs, core bancario, sistemas sanitarios.
- Cualquier workload donde el coste del downtime supera con creces el sobrecoste de la replicación.
6. RA-GZRS – Read-Access Geo Zone Redundant Storage
Objetivo: GZRS + endpoint de lectura en la secundaria. Es la «edición de lujo» de todas las opciones.
Mismas consideraciones que RA-GRS para lecturas en secundaria (cuidado con el egress), pero con la protección extra de ZRS en la primaria.
Hablemos de RPO y RTO
Quizás estos términos te suenen a chino. Pero si llevas tiempo en ciberseguridad sabrás que la disponibilidad es una de las tres patas de la tríada CIA (junto con confidencialidad e integridad), y RPO y RTO son justo las métricas que la cuantifican. Aquí va la versión rápida:
- RPO (Recovery Point Objective) – ¿Cuántos datos puedo permitirme perder, expresado en tiempo?
- RTO ((Recovery Time Objective) – ¿Cuánto puedo permitirme estar caído?
Para opciones síncronas (LRS, ZRS):
- RPO = 0 → no pierdes nada, todas las copias están actualizadas antes de confirmar la escritura.
- RTO depende del tipo de fallo, pero el failover es transparente.
Para opciones geo-redundantes (GRS, GZRS y sus RA-):
- RPO ≤ 15 minutos típicamente, pero Microsoft NO lo garantiza por SLA. La replicación es asíncrona, así que siempre puedes perder los últimos segundos/minutos de escrituras.
- RTO de failover ≈ 30-60 minutos (manual, lo lanzas tú).
A tener muy en cuenta: si tu negocio exige RPO = 0 cross-region (GRS y GZRS), Azure Storage por sí solo no te lo da. Necesitas patrones a nivel de aplicación (escrituras dobles, event sourcing, etc.) o servicios como Cosmos DB con multi-region writers.
¿Qué pasa realmente durante un failover?
La pregunta del millón o la otra versión, la parte que muchos no se leen y luego se llevan alguna que otra sorpresita. Vamos paso a paso:
- Failover gestionado por Microsoft: Solo ocurre en catástrofes extremas que afecten a una región entera y tras múltiples intentos fallidos de recuperación. Ni se te ocurra contar con esto como tu estrategia de DR. Microsoft tarda días en tomar esa decisión.
- Failover gestionado por ti (este es el bueno):
- Tú decides hacer el failover (desde el portal, CLI, PowerShell o incluso API).
- Azure cambia los registros DNS para que tu endpoint primario apunte a la región secundaria.
- Tus URLs no cambian, parece genial, ¿no?, pero solo parece…
- Aquí viene el palo: tras el failover, tu cuenta se convierte automáticamente en LRS en la nueva región primaria. La geo-redundancia se rompe.
- Para volver a tenerla, toca reconfigurar manualmente la cuenta a GRS/GZRS, lo que implica:
- Coste adicional (hay que replicar los datos de nuevo).
- Tiempo (puede tardar mucho, dependiendo del volúmen).
- Si tenías blobs en archive tier, hay que «rehidratarlos primero» (más coste, más tiempo).
- La cuenta original (la que se cayó) se elimina cuando vuelve a estar disponible. Así es y así se lo hemos contado…
El comando para iniciar el failover de forma manual, a la región secundaria, es bastante sencillo y como cabría de esperar, es algo tal que así:
### Comando rápido para iniciar un failover:
```bash
az storage account failover \
--name micuenta \
--resource-group mi-rg
```Una recomendación y es algo que también pocos tienen en cuenta: prueba el failover antes de necesitarlo. Azure tiene la opción de «planned failover» que te deja ensayar todo el proceso sin perder datos. Si solo pruebas tu DR en producción la primera vez que se cae todo, ten preparada la cafetera, porque intuyo que te espera una noche muy larga.
Framework de decisión rápido
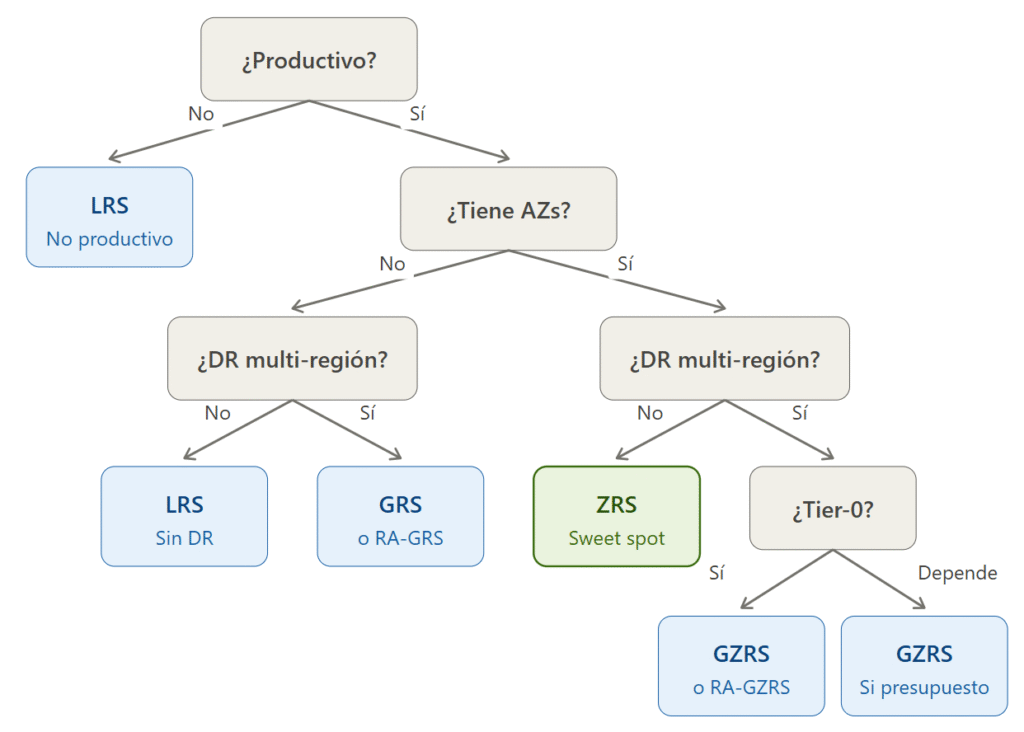
Limitaciones que pueden desconcertar
Apúntate esto que me lo agradecerás:
- No todas las regiones soportan todas las opciones. Por ejemplo, GZRS requiere que la región tenga AZs y que esté emparejada. Verifica antes de planificar.
- Azure Files Premium (SSD) solo soporta LRS y ZRS. Si necesitas geo-redundancia en File Shares Premium, hay que diseñar replicación a nivel de aplicación.
- El archive «tier» solo está disponible en cuentas LRS, GRS y RA-GRS. No funciona con ZRS/GZRS/RA-GZRS.
- Los discos no gestionados (legacy) no soportan ZRS ni GZRS. Migra a discos administrados ya, en serio.
- Cambiar la replicación tiene coste. Pasar de LRS a GRS implica replicar todo el contenido a la otra región → tarda y se factura.
- El SLA de escritura es siempre 99.9%+, independientemente de la opción. Las opciones más redundantes mejoran la durabilidad y la disponibilidad de lectura, no necesariamente la de escritura.
Recomendaciones finales:
Si tengo que resumir 20 años de «lo aprendí por las malas» en cinco puntos:
- No pagues seguros que no necesitas. GZRS para un entorno de dev es tirar dinero.
- No escatimes en tier-0. Si tu negocio depende del dato, GZRS o RA-GZRS no es opcional.
- Diseña pensando en RPO != 0. Si tu app no puede tolerar perder 15 minutos de datos, Storage por sí solo no es la solución.
- Pruebal el failover. Si no lo has probado, no funciona – Demoledor.
- Replicación <> Backup. Por favor, repítetelo. Replicación. No. Es. Backup.
Documentación oficial
Las fuentes de Microsoft Learn en las que se basa este post:
[Redundancia de datos en Azure Storage] — la referencia maestra de LRS/ZRS/GRS/GZRS.
[Planificación de recuperación ante desastres y failover]
[Funcionamiento del failover no planificado gestionado por el cliente]
[Fiabilidad en Azure Blob Storage]
[Precios de Azure Storage (para comparar costes por opción)]
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.