
Introducción
¡Hola comunidad!. Si llevas un tiempo trasteando con Azure, seguro que has visto siglas como LRS, ZRS, GRS o GZRS rondando por la documentación de Storage Accounts. Y probablemente te ha pasado lo mismo que a mí en mis primeros despliegues: copiar la opción «que parece la buena» sin entender del todo qué hay detrás. La clave está en entender la infraestructura de Azure, porque casi todas esas decisiones dependen de cómo está montada físicamente por debajo.
Antes de meternos de lleno en las opciones de replicación (que será el siguiente post), necesitamos sentar las bases. Porque cuando entiendes cómo está construida físicamente la infraestructura de Azure, las opciones de replicación dejan de ser un menú desplegable confuso y se convierten en decisiones arquitectónicas con sentido.
Vamos al lío.
La infraestructura de Azure es como una muñeca rusa
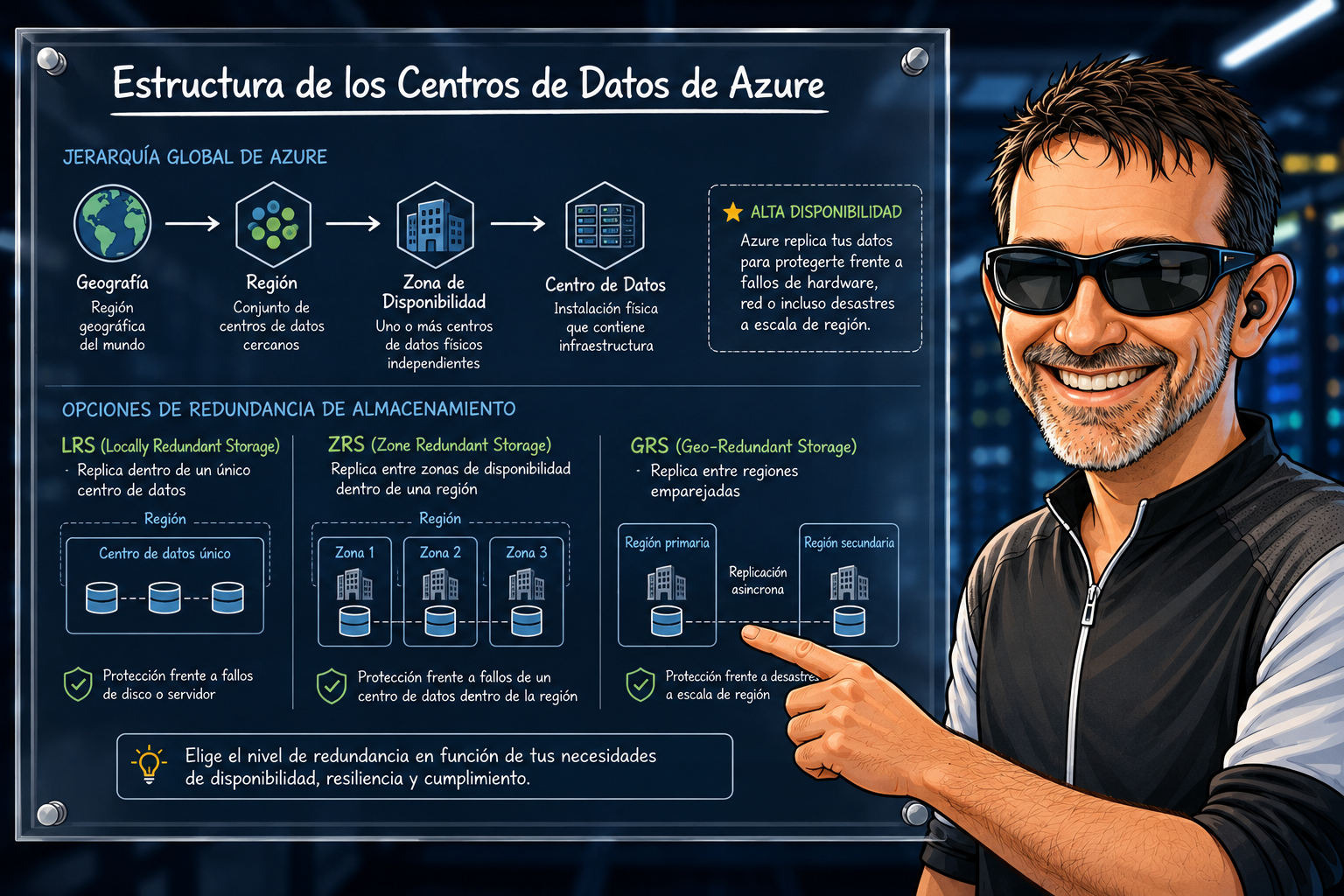
La forma más fácil de visualizar la infraestructura de Azure es pensar en «cajas dentro de cajas». Cada nivel nos da un tipo distinto de aislamiento y, por tanto, un tipo distinto de resiliencia.
De fuera hacia dentro tenemos:
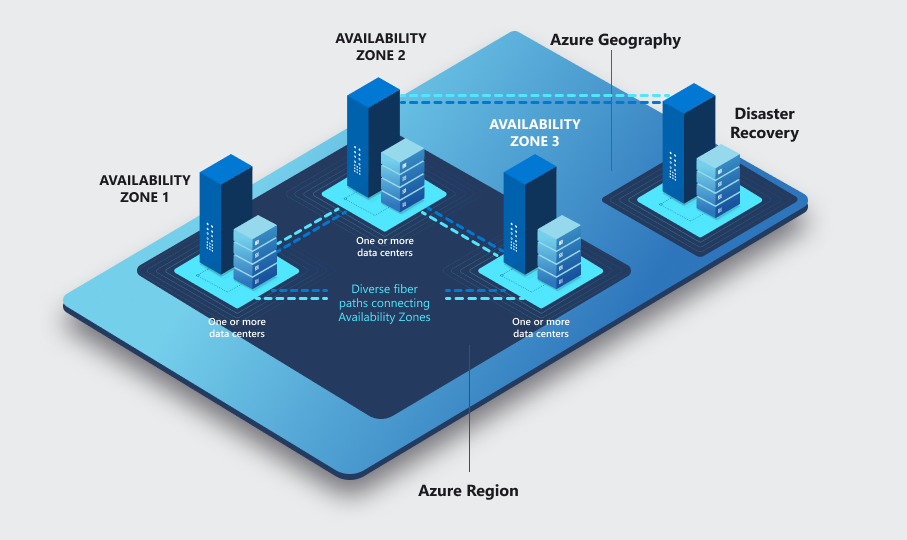
De fuera hacia dentro tenemos:
🌐 Geografía
└── 🗺️ Región (+ región emparejada)
└── 🏢 Zona de Disponibilidad
└── 🖥️ Centro de Datos (Datacenter)
veamos nivel a nivel.
Geografía
Una «geografía» es una agrupación de regiones que normalmente se corresponde con un país o una zona económica concreta: España, Europa, Estados Unidos, Brasil, India…
¿Por qué existe este concepto? Pues por una razón muy concreta: «residencia y soberanía del dato». Si una normativa (RGPD, esquemas nacionales, etc.) te obliga a que tus datos no salgan de la Unión Europea, la geografía es la frontera que te garantiza ese requisito.
Tip: Cuando un cliente te diga «estos danos no pueden salir de España», inmediatamente debemos asociar en nuestra mente el concepto de «geografía».
Es el nivel más alto de toda la infraestructura de Azure y el que marca dónde residen legalmente tus datos.
Listado completo de geografías y regiones disponibles
Región
Una «región» es lo que normalmente seleccionas en el portal cuando despliegas un recurso: «West Europe», «Spain Central», «North Europe», «East US 2″…
Formalmente, una región es un «conjunto de centros de datos desplegados dentro de un perímetro definido por latencia y conectados por una red regional dedicada de baja latencia». Es decir: no es un único edificio, es un campus (o varios) dentro de un radio relativamente cercano.
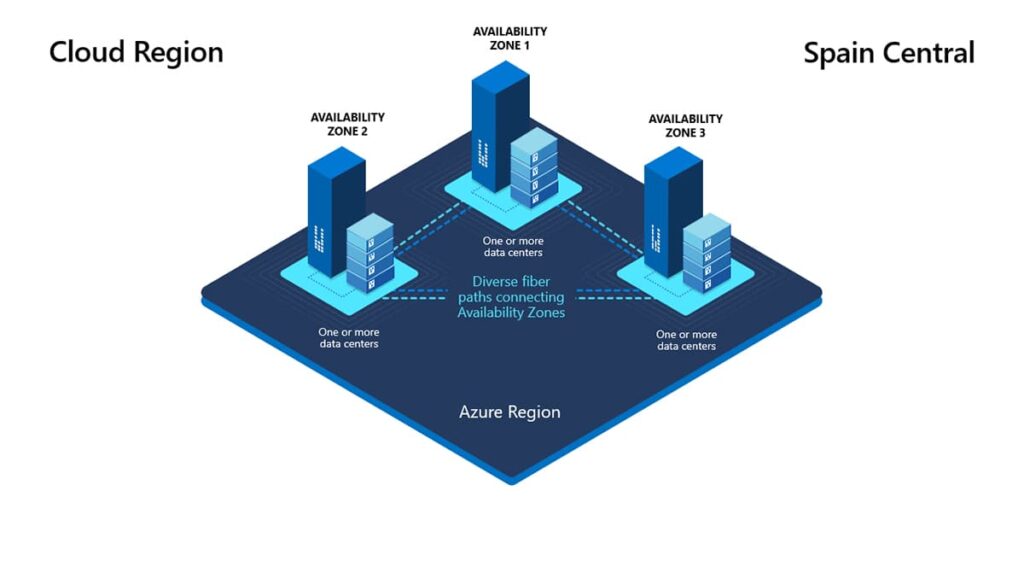
Hoy Azure cuenta con más de «60 regiones» en producción y sigue creciendo. España, por ejemplo, tiene «Spain Central», que es una región relativamente joven pero con zonas de disponibilidad desde su lanzamiento.
¿Regiones emparejadas?
Si y es un detalle importante que mucha gente desconoce. La mayoría de regiones de Azure están emparejadas con otra región dentro de la misma geografía, normalmente a más de 480 km de distancia (300 millas).
Algunos ejemplos clásicos que me vienen a la mente:
| Región primaria | Región secundaria |
| North Europe | West Europe |
| West Europe | North Europe |
| East US | West US |
| France Central | France South |
Y para qué este concepto, porqué ¿Regiones emparejadas?, básicamente son tres los motivos:
- Replicación automática: Servicios como Geo-Redundant Storage (GRS) replican tus datos a la región emparejada «sin necesidad de hacer nada más».
- Actualización secuenciales: Azure nunca actualiza las dos regiones de un par al mismo tiempo. Es decir, en el evento de una actualización, Microsoft planifica dicha actualización de forma escalonada.
- Prioridad de recuperación: En el caso (bastante improbable, pero…) de una caída masiva, Azure prioriza la recuperación «al menos de una región de cada par». Si tienes tu DR en una región no emparejada, podrías estar al final de la cola.
Cuidado porque no todas las regiones tienen pareja. Las regiones más nuevas a veces se lanzan como *non-paired regions* (caso de Spain Central), y en esos casos la replicación geográfica hay que diseñarla manualmente eligiendo una región secundaria. Esto no es malo, simplemente es algo que tienes que tener en cuenta.
Zonas de disponibilidad
Aquí es donde empieza la magia para la alta disponibilidad dentro de una región.
Una Zona de Disponibilidad (AZ) es un grupo de uno o más centros de datos físicamente separados dentro de la misma región, cada uno con su propia alimentación eléctrica, refrigeración y red completamente independientes.
Las regiones que soportan AZs tienen al menos tres zonas, etiquetadas normalmente como 1, 2 y 3, como el caso de Spain Central.
Las características claves de cada Zona:
- Distancia: las zonas suelen estar separadas por varios kilómetros, normalmente dentro de un radio de 100 km. Lo suficientemente cerca para tener buena latencia, lo suficientemente lejos para que un incidente físico (incendio, inundación) no las afecte a todas.
- Latencia inter-zona: Microsoft garantiza menos de 2 ms de «round-trip» entre zonas. Esto permite «replicación síncrona» entre AZs sin penalizar apenas el rendimiento.
- Aislamiento de fallos: si la zona 1 se cae (corte eléctrico, problema de red…), las zonas 2 y 3 siguen funcionando como si nada.
Servicios zonales vs zona-redundantes
Este concepto nos lo vas a encontrar en la documentación constantemente, así que es importante tenerlo en cuenta:
- Recurso zonal: tú eliges en qué zona se despliega el recurso (típico de máquinas virtuales, discos managed, IPs estáticas estándar).

- Zona redundante (ZRS): Azure replica el recurso entre las tres zonas automáticamente (típico de Storage Accounts, SQL Database, etc.).

Ambos son válidos, pero resuelven problemas distintos. Si quieres resiliencia «sin pensar», busca servicios zona-redundantes. Si necesitas control fino (por ejemplo, para distribuir nodos de un cluster), tira de zonales.
Detalle curioso: la zona 1 de tu suscripción no es necesariamente la misma zona física que la zona 1 de la suscripción de otro compañero. Microsoft hace un mapeo lógico distinto por suscripción para balancear carga. Si necesitas saber el mapeo real entre suscripciones, hay una API llamada «Check Zone Peers» para consultarlo.
Centros de Datos (Datacenters)

Y llegamos al nivel más bajo: el propio edificio físico. Las naves con servidores, racks, sistemas de refrigeración, generadores diésel y todo el aparataje.
Azure no te deja elegir un centro de datos concreto, ni te dice exactamente dónde está cada uno (por seguridad). Lo que sí sabemos públicamente:
- Microsoft opera más de 300 centros de datos repartidos por todo el mundo.
- Cada zona de disponibilidad puede tener uno o varios centros de datos.
- Están interconectados mediante una red de fibra propia que supera los 280.000 km (sí, has leído bien).
Para ti, como arquitecto o desarrollador, el datacenter es una caja negra. Tu unidad mínima es la zona de disponibilidad, no el edificio.
Cómo la infraestructura de Azure conecta con la replicación
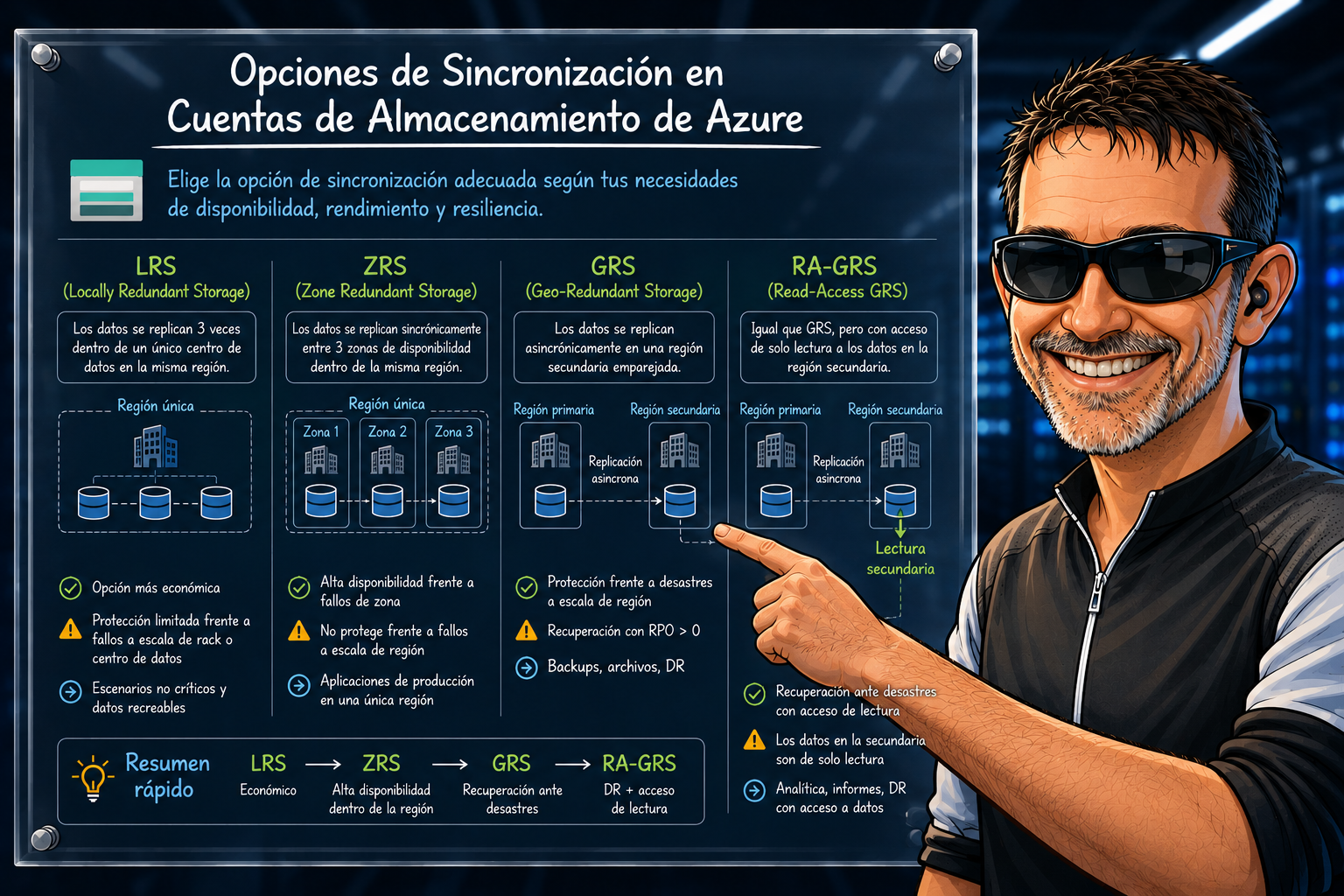
Aquí está la chicha del asunto. Cuando, por ejemplo, en Storage Account te aparecen estas opciones:
| Opción | ¿Qué hace? | ¿Contra qué protege? |
| LRS (Locally Redundant Storage) | 3 copias repartidas en el mismo centro de datos de la región primaria | Fallo de disco, servidor o rack |
| ZRS (Zone Redundant Storage) | 3 copias repartidas entre 3 AZs | Caída de una zona completa |
| GRS (Geo Redundant Storage) | LRS + copia asíncrona a la región emparejada | Caída de una región entera |
| GZRS (Geo Zone Redundant Storage) | ZRS + copia asíncrona a la región emparejada | Caída de zona **y** de región |
Ahora ya podemos tener nuestro esquema mental de como mapea cada nivel con nuestra «muñeca rusa» (infraestructura de Azure) anterior. El truco está en que no se trata de elegir siempre la opción más cara/redundante, sino la que se ajusta al RPO, RTO y presupuesto de cada workload. Por tanto las preguntas típicas que deberíamos hacernos antes de seleccionar un nivel son básicamente tres:
- ¿Es un entorno de desarrollo donde puedes reconstruir los datos? → LRS y a otra cosa.
- ¿Es producción, pero sin requisitos de DR cross-region? → ZRS suele ser la mejor opción.
- ¿Es un sistema crítico que tiene que sobrevivir a un terremoto en Madrid? → GZRS.
¿Qué viene en el próximo post?
Ahora que tienes clara la infraestructura de Azure sobre la que se sustenta todo, en la Parte 2 vamos a meternos a fondo con las opciones de replicación de Storage Accounts, viendo casos prácticos, costes asociados, cuándo elegir cada una y qué pasa realmente cuando ocurre un failover (spoiler: no es magia, y hay cosas que tienes que hacer tú).
¡Nos vemos en la próxima!
Documentación oficial
– [Azure global infrastructure – Geographies](https://azure.microsoft.com/en-us/explore/global-infrastructure/geographies/)
– [Lista de regiones de Azure (con parejas y soporte de AZs)](https://learn.microsoft.com/en-us/azure/reliability/regions-list)
– [Region pairs y regiones no emparejadas](https://learn.microsoft.com/en-us/azure/reliability/regions-paired)
– [¿Qué son las zonas de disponibilidad de Azure?](https://learn.microsoft.com/en-us/azure/reliability/availability-zones-overview)
– [Soluciones multi-región en regiones no emparejadas](https://learn.microsoft.com/en-us/azure/reliability/regions-multi-region-nonpaired)
– [Redundancia de datos en Azure Storage](https://learn.microsoft.com/en-us/azure/storage/common/storage-redundancy)
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.