
Hay un momento que se repite muchísimo cuando empiezas a trabajar con agentes.
Ese momento en el que haces una demo, ves que responde bien, sonríes… y piensas:
“Vale, esto pinta bien” ✨
Pero justo después llega la pregunta de verdad:
“¿Y cómo sé que va a seguir funcionando bien cuando lo saque a producción?”
Y ahí cambia todo.
Porque una demo bonita puede salir bien un día.
Lo difícil no es eso.
Lo difícil es tener la tranquilidad de que el agente va a responder con calidad, con consistencia y sin sorpresas cuando ya forme parte de un proceso real de negocio.
Durante mucho tiempo, validar agentes se parecía demasiado a ir “un poco a ojo”: abrir el panel de pruebas, lanzar unas cuantas preguntas típicas, comprobar que la respuesta parecía razonable… y confiar. Pero cuando empiezas a hablar de entornos reales, de clientes y de procesos importantes, la intuición se queda corta.
Y justo por eso me parece tan interesante Agent Evaluation en Microsoft Copilot Studio: porque nos obliga a dar un paso adelante. A dejar atrás el “yo diría que funciona” para empezar a trabajar con algo mucho más valioso: evidencias 💡
Por qué evaluar un agente ya no es opcional
Los agentes no son software determinista al uso. Su comportamiento puede cambiar según el modelo, el contexto, las instrucciones, las fuentes de conocimiento o incluso los recursos a los que acceden.
Y ahí está la clave: cuando el agente evoluciona, la forma de validarlo también tiene que evolucionar.
Ya no basta con decir “parece que funciona”.
Ahora toca poder decir: “lo hemos medido, lo hemos comparado y tenemos evidencias”.
Evaluar un agente no va de desconfiar de la IA. Va de dejar de trabajar a ciegas.
Qué es Agent Evaluation en Microsoft Copilot Studio
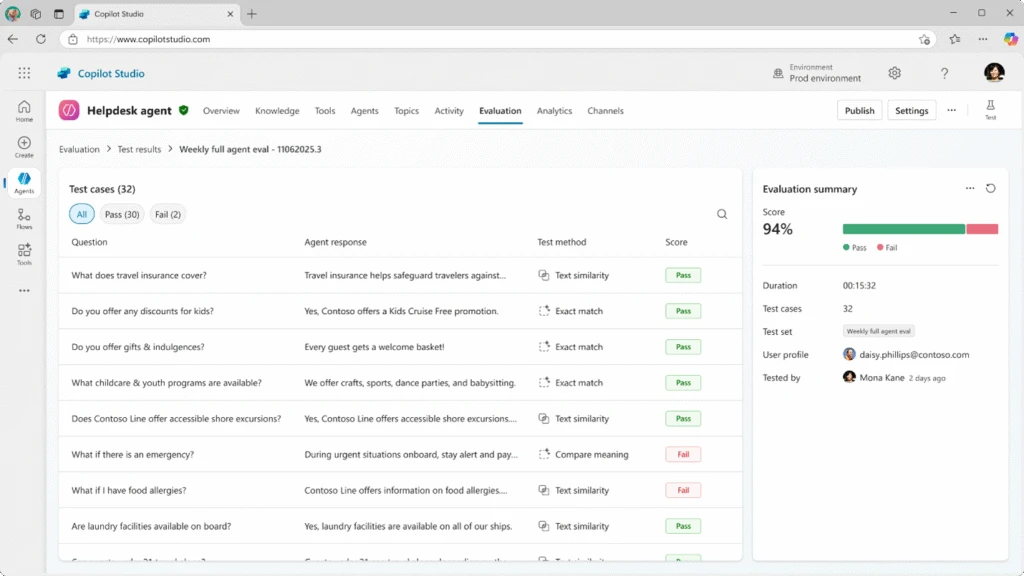
Agent Evaluation es la funcionalidad de Microsoft Copilot Studio que permite probar un agente con un enfoque mucho más estructurado. La idea es crear conjuntos de pruebas, elegir métodos de evaluación, ejecutar tests y revisar resultados sin salir de la propia herramienta.
La pieza clave aquí es el test set.
Un test set es un conjunto de casos de prueba que simulan cómo interactuaría una persona con tu agente. Puede ser una pregunta aislada o incluso una conversación completa. Y lo importante es que ese conjunto se puede reutilizar una y otra vez para comparar resultados después de cambios.
Y eso, cuando trabajas con agentes de verdad, vale muchísimo.
Cómo se crean los test sets
Una de las cosas más potentes de este enfoque es que no tienes que montarlo todo a mano.
Puedes crear test sets:
- Escribiendo preguntas manualmente
- Reutilizando interacciones recientes del panel de pruebas
- Importando preguntas desde archivo
- Generando preguntas automáticamente con IA a partir de la metadata, las instrucciones y las fuentes de conocimiento del propio agente
Y esto cambia bastante el juego. Porque ya no estás validando “sensaciones”. Estás validando escenarios.
Métodos de evaluación: no todo se mide igual 💜
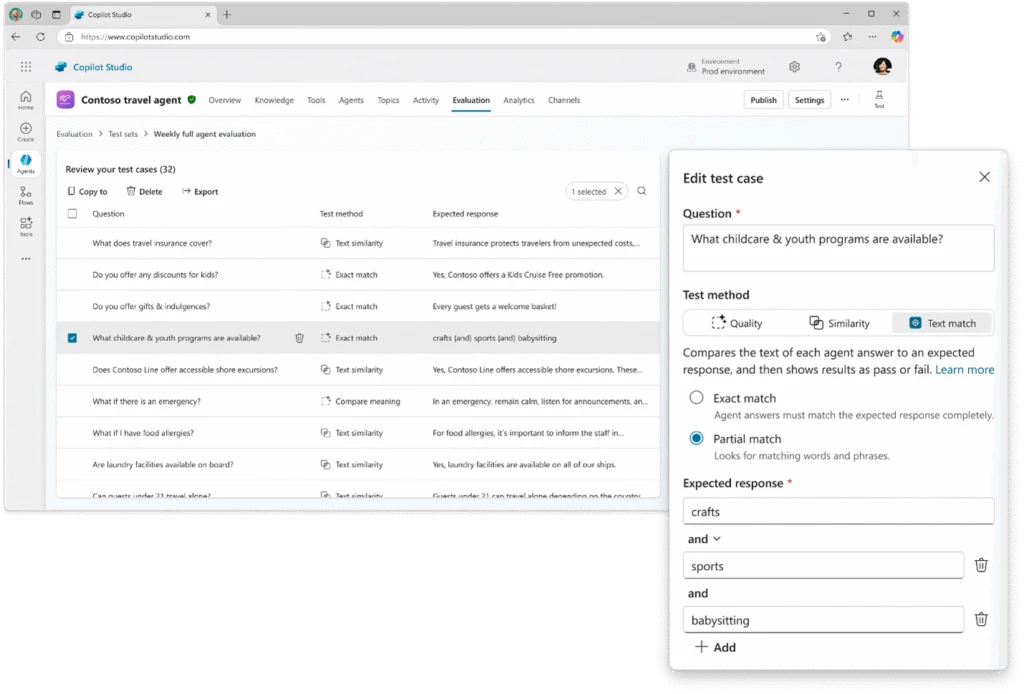
Aquí está, para mí, uno de los puntos más interesantes.
No todos los agentes necesitan el mismo tipo de validación. Y Copilot Studio no te obliga a medirlo todo con la misma regla. Según el caso, puedes apoyarte en métodos como General quality, Compare meaning, Capability use, Keyword match, Text similarity, Exact match o incluso evaluaciones Custom.
General quality
Es especialmente útil cuando no existe una única respuesta exacta. Aquí lo que se valora es si la respuesta es relevante, está bien fundamentada, es suficientemente completa o sabe abstenerse cuando toca.
Compare meaning
Este método no exige que la respuesta coincida palabra por palabra, sino que transmita el significado correcto. Es muy útil cuando hay varias formas válidas de responder bien.
Capability use
Aquí lo importante es comprobar si el agente ha usado las herramientas o capacidades esperadas para responder. Y eso, en escenarios con grounding, acciones o acceso a recursos concretos, puede marcar bastante diferencia.
Keyword match, Text similarity y Exact match
Estos métodos son más rígidos, pero justamente por eso también son muy útiles cuando necesitas validar respuestas cerradas.
- Keyword match comprueba si aparecen determinados términos
- Text similarity compara el parecido con una respuesta esperada
- Exact match exige coincidencia exacta, así que encaja muy bien en respuestas fijas, códigos o cifras
Custom
Y esta parte me parece especialmente potente: también puedes crear evaluaciones Custom con tus propios criterios. Por ejemplo, para revisar tono, cumplimiento, políticas internas o reglas específicas de negocio.
Lo importante no es solo probar: es poder comparar 🔁
Una evaluación útil no termina en un porcentaje bonito.
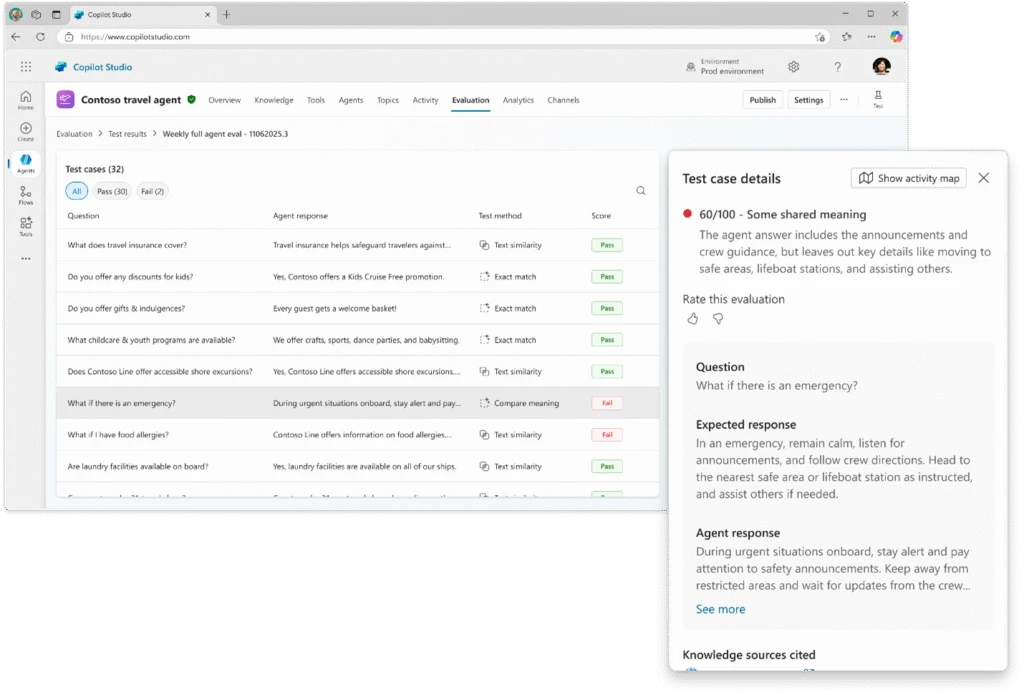
El valor real está en poder ejecutar el mismo conjunto de pruebas, revisar el detalle de cada caso, comparar resultados y entender si un cambio ha mejorado el comportamiento del agente… o lo ha roto sin que nadie se diera cuenta.
Y aquí está el verdadero cambio:
Evaluar, ajustar, volver a evaluar y comparar.
Eso ya se parece bastante más a una práctica seria de calidad. Y también a una conversación mucho más madura con negocio.
Lo que Agent Evaluation sí es… y lo que no
Aquí conviene dejar algo muy claro.
Agent Evaluation no sustituye las revisiones de Responsible AI ni los filtros de seguridad.
Es una pieza clave, sí. Pero no resuelve por sí sola problemas de ética, safety, cumplimiento o respuestas inapropiadas en contextos sensibles.
Dicho de otra forma: no es toda la estrategia, pero sí es una pieza imprescindible del puzzle.
Tres preguntas inevitables cuando hablamos de evaluación de agentes
Hasta aquí, la idea está clara: qué es Agent Evaluation, por qué importa y por qué ya no deberíamos validar un agente como algo improvisado.
Pero cuando bajas todo esto a un proyecto real, siempre aparecen las mismas preguntas. Y, sinceramente, son muy buenas preguntas.
¿Cada cuánto tiempo hay que evaluar un agente?
Aquí, para mí, hay una idea importante: la evaluación no debería entenderse como una tarea fija de calendario, sino como una práctica continua a lo largo de la vida del agente.
Hay tres momentos en los que evaluar debería ser casi innegociable:
Antes de llevar el agente a producción.
Porque ahí dejamos de probar “a ver qué tal” y empezamos a asumir responsabilidad de verdad.
Después de cualquier cambio relevante.
Un ajuste en el prompt, en las instrucciones, en el modelo, en las herramientas o en las fuentes de conocimiento puede cambiar más de lo que parece el comportamiento del agente.
De forma recurrente durante su vida útil.
Porque los agentes no son estáticos. Evolucionan con el negocio, con el contexto y con el uso.
La idea de fondo es bastante simple:
Si el agente cambia, se evalúa.
Si el contexto cambia, se evalúa.
Y si no tienes claro si algo ha cambiado, probablemente también conviene evaluarlo.
¿La evaluación es automática o hay que lanzarla a mano?
Aquí suele haber bastante confusión.
La ejecución de la evaluación es automática.
Pero el disparador no lo es.
Es decir: una vez definido el test set, Copilot Studio puede encargarse de lanzar las preguntas, simular las conversaciones, evaluar las respuestas y devolverte resultados. Pero eso no significa que la evaluación viva sola en segundo plano sin que nadie la gobierne.
Y, sinceramente, mejor así.
Porque la evaluación no está pensada para sustituir el criterio del equipo, sino para reforzarlo con datos. Forma parte natural del ciclo de construir, probar, ajustar y volver a probar.
Además, cada ejecución deja rastro. Y eso importa mucho cuando quieres comparar resultados, detectar tendencias y tener evidencias trazables.
¿Quién debería encargarse de evaluar un agente?
Otra idea importante: evaluar un agente no es solo cosa del desarrollador.
Sí, makers y desarrolladores suelen construir los primeros test sets y validar el comportamiento más técnico. Pero no deberían ser los únicos.
También tiene sentido que participen:
- Equipos de QA o calidad, cuando la organización ya tiene cierto nivel de madurez
- Responsables del agente, aunque no lo hayan construido directamente
- Equipos de gobernanza o compliance, cuando hacen falta evidencias claras antes del despliegue
Y hay un matiz especialmente importante en entornos corporativos: las evaluaciones pueden hacerse teniendo en cuenta perfiles de usuario concretos, lo que permite validar comportamientos según permisos y accesos reales.
Porque en empresa, seamos honestas, el “depende del usuario” no suele ser la excepción. Suele ser la norma.
Entonces, ¿qué cambia realmente?
Cambia mucho.
Desde el lado de negocio, evaluar bien un agente significa desplegar con más confianza, detectar antes cuándo algo se ha roto y justificar mejor que ese agente está preparado para entrar en procesos reales.
Desde el lado maker o técnico, significa dejar atrás el clásico “yo diría que esto iba bien” y empezar a trabajar con una base mucho más objetiva.
Y eso cambia la conversación por completo ✨
Conclusión: menos fe, más evidencias
Para mí, esta es la idea con la que hay que quedarse:
evaluar agentes en Microsoft Copilot Studio no va de desconfiar de la IA. Va de dejar de trabajar a ciegas.
Va de iterar con datos.
Va de comparar resultados reales.
Va de detectar problemas antes.
Y va de poder llevar un agente a producción con mucha más tranquilidad.
Porque sí, las demos bonitas están muy bien. Pero cuando hablamos de agentes de verdad, lo que da confianza no es la intuición.
Son las evidencias 💜
Fuentes
- Microsoft Copilot Blog. Build smarter, test smarter: Agent Evaluation in Microsoft Copilot Studio
https://www.microsoft.com/en-us/microsoft-copilot/blog/copilot-studio/build-smarter-test-smarter-agent-evaluation-in-microsoft-copilot-studio/ - Microsoft Learn. About agent evaluation
https://learn.microsoft.com/en-us/microsoft-copilot-studio/analytics-agent-evaluation-intro - Microsoft Learn. Agent evaluation overview
https://learn.microsoft.com/en-us/microsoft-copilot-studio/analytics-agent-evaluation-overview - Microsoft Learn. Generate and import test sets for agent testing
https://learn.microsoft.com/en-us/microsoft-copilot-studio/analytics-agent-evaluation-create - Microsoft. Microsoft Copilot Studio
https://www.microsoft.com/en-us/microsoft-365-copilot/microsoft-copilot-studio
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.