

¿Qué es el Web Scraping?
En la era digital, los datos se han convertido en uno de los recursos más valiosos para empresas, investigadores y desarrolladores. Sin embargo, gran parte de esa información se encuentra dispersa en páginas web, difícil de recopilar de manera manual y poco práctica para proyectos que requieren volumen o actualización constante.
A todo esto se suma una limitación importante: cuando intentamos conectar nuestras fuentes de conocimiento en formato URL, nos encontramos con la restricción de navegación a solo dos niveles impuesta por la IA. En la práctica, esto significa que no es posible acceder directamente a rutas más profundas, como , quedando inaccesible el contenido en el tercer nivel y posteriores.
Este obstáculo nos obliga a replantear la estrategia y recurrir a herramientas adicionales que permitan enriquecer a nuestros agentes con el conocimiento extraído de esas capas más profundas. Solo así conseguimos dotarlos de la información completa y relevante que necesitan para operar de manera eficaz.
Sin entrar a valorar si éticamente es lícito o moralmente adecuado usar contenido de terceros para nutrir nuestra inteligencia artificial con el mismo, vamos a ver cómo podemos utilizar cualquier origen, saltándonos la limitación de dos niveles impuesta.
Sabor…. Python
Hoy en día, hablar de la IA sin Python es imposible. Eso sí, no hay que asustarse: tenemos .NET C# para muchos años. Pero no debemos olvidar que, en muchos casos, el código limpio y directo de Python, además de sus múltiples funcionalidades, nos aporta ese plus, esa agilidad para acometer procesos de diferente índole cuando hablamos de inteligencia artificial.
En esta entrada queremos plantear un ejemplo real sobre una casuística que nos hemos encontrado, y que ya expusimos mi compañero Ramón Palomares y yo en la pasada NetCoreConf de Madrid: la posibilidad de obtener información diaria publicada en el BOE.
El principal problema con el que nos encontramos es el elevado número de niveles que presenta la web pública, la cual mantiene este formato:
boe.es/boe/dias/year/month/day (obviamente pasa los 2 niveles)
He aquí que tenemos que recurrir a herramientas de terceros, y más concretamente a Python y su librería BeautifulSoup, la cual nos permite extraer el contenido HTML de cualquier web:
from bs4 import BeautifulSoup
Con dicha herramienta podremos, desde un origen web, extraer su contenido. Pero en el caso que nos ocupa, la necesidad es que, mediante Copilot Studio, podamos hacerle preguntas a nuestro agente en lenguaje natural y que este sea capaz de respondernos con contenido sobre el BOE, incluso facilitándonos los metadatos (la URL del documento donde se encuentra tu consulta).
Llegados a este punto, ya tenemos todo el contenido de la web del BOE para un día concreto extraído, pero aún solo contamos con una página principal, tal que así:
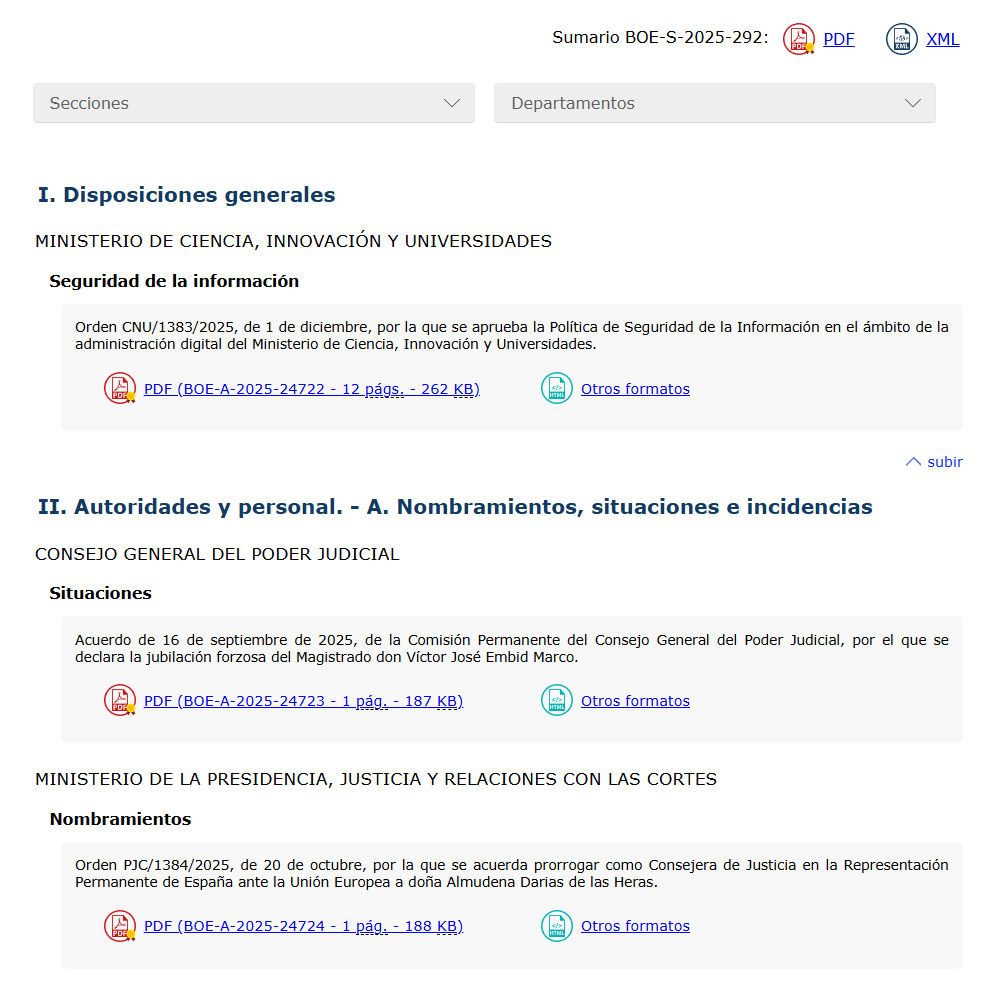
Es decir, tenemos los enlaces a los diferentes PDFs del día en cuestión seleccionado, pero ¿realmente esta es la información que necesitamos? Lógicamente no: la información real está contenida en los diferentes PDFs; aquí únicamente tenemos los enlaces.
Haciendo uso de BeautifulSoup, tenemos la posibilidad de buscar en el contenido. Dicho y hecho, pasamos a localizar los diferentes enlaces
resp = requests.get(boe_url)
soup = BeautifulSoup(resp.text, "html.parser")
pdf_links = [a['href'] for a in soup.find_all('a', href=True) if a['href'].lower().endswith('.pdf')]
pdf_links = [link if link.startswith("http") else f"https://www.boe.es{link}" for link in pdf_links]
Donde, si os fijáis, tendremos un array o lista en la que guardaremos todos los enlaces que apunten a una URL terminada en .pdf. Llegados a este punto, ya tenemos todos los PDFs que necesitamos escudriñar y extraer con toda su información. Para hacerlo, pasaremos cada URL de PDF a otra librería de Python, en este caso Pdfplumber, que será la encargada de leer y extraer los datos contenidos en los PDFs.
for link in pdf_links:
try:
print(f"📄 Procesando: {link}")
max_retries = 3
for attempt in range(max_retries):
try:
response = requests.get(link)
response.raise_for_status()
pdf_file = BytesIO(response.content)
break
except requests.exceptions.RequestException as e:
wait = 2 ** attempt
logging.warning(f"🔁 Reintentando {link} en {wait} segundos (intento {attempt + 1}/{max_retries})...")
time.sleep(wait)
else:
logging.error(f"❌ Fallo al descargar PDF tras {max_retries} intentos: {link}")
continue
pdf_file = BytesIO(response.content)
with pdfplumber.open(pdf_file) as pdf:
full_text = ""
for page_num, page in enumerate(pdf.pages):
text = page.extract_text()
if text:
full_text += text + "\n"
else:
print(f"⚠️ Página {page_num + 1} sin texto extraíble.")
Una vez tengamos el bruto de todo el contenido en texto de los PDFs disponibles en una fecha del BOE, la pregunta es la siguiente: estamos en el camino, pero con esto, ¿qué podemos hacer? o ¿cómo podríamos alimentar con esta información a nuestro Copilot Studio?
Vectorización y lenguaje natural
Con todo este texto “bruto” necesitamos ser capaces de poder “enchufárselo” como origen de conocimiento, ya sea a mi Copilot Studio o a mi Agent en Azure Foundry. En ambos casos, la mejor opción es la vectorización, es decir, convertir nuestro texto en un vector multidimensional para que nuestro Copilot sea capaz de entenderlo y, mediante proximidad, obtener los resultados óptimos.
En este punto necesitamos una pieza clave, que es Azure Foundry, y un modelo esencial, Ada. Este modelo nos permite pasar un texto y obtener como resultado un array de embeddings.
Los modelos Ada, como cualquier modelo, tienen sus limitaciones. Por ejemplo, el número máximo de tokens que podemos pasarles. Lo normal es que algunos de nuestros PDFs, que son bastante largos, lo superen y se produzcan errores.
Es por eso que usamos la terminología “chunk”, es decir, vamos a trocear el texto extraído en cadenas. Pero entonces surge la pregunta: ¿qué hacemos con ellas?
AI Seach
Otra pieza fundamental en este proceso es AI Search. Esta herramienta nos permitirá indexar y obtener información de manera sumamente rápida, para poder ser consumida como “fuente de alimentación” en los diferentes Copilots y agentes.
Como ya hemos hablado de indexar, lo primero que debemos crear es un índice. En este caso, para que se genere la estructura correcta sin tener que utilizar skills —que en el momento de realizar la sesión práctica aquí comentada aún fallaban— lo ideal es usar la opción Import Data, tal que así:
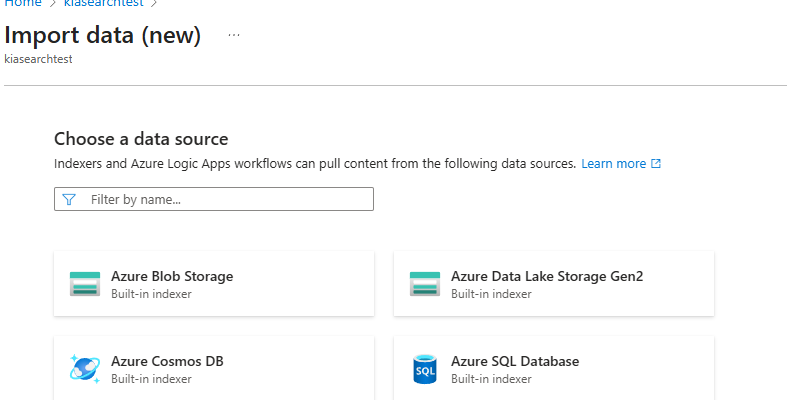
Esta opción se accede desde Overview de nuestro Azure Search AI
Pero antes de crear nuestro índice, y dado que tenemos en mente realizar la vectorización (embedding), será necesario crear un modelo en el que podamos apoyarnos para efectuar dicha conversión.
Por ello, debemos crear un recurso de OpenAI, y dentro de su Foundry:
Debemos generar una implementación de tipo ADA, que son los modelos que nos permiten realizar la vectorización:
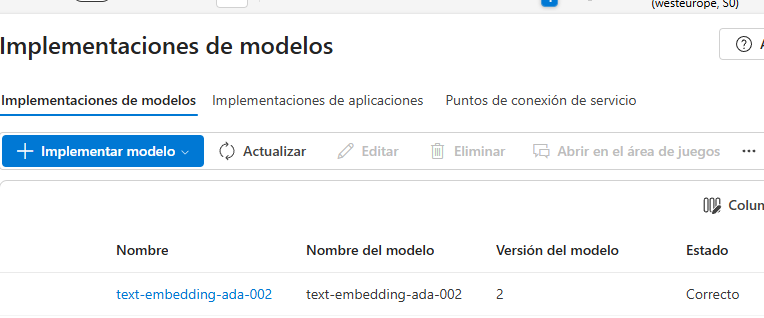
Una vez que tenemos el modelo, y volviendo al punto donde nos habíamos quedado, podremos generar el índice, activando la generación vectorial. Cuando nos pregunte por el modelo, utilizaremos el creado en este punto.
Ese índice lo vamos a crear en función, como comentaba, de un fichero PDF del BOE descargado, porque nos proporcionará todas las propiedades necesarias y nos activará los skills y la indexación.
Ahora mismo, justamente en este punto ya tendríamos una fuente de datos de consulta correcta para conectar a nuestro Copilot Studio, pero ¿únicamente con datos de un doc? , sí…. Pero espera un poco.
Copilot Studio + Azure Seach
Si nos vamos hacia nuestro Copilot Studio y decidimos, tal y como debe ser, crear un nuevo agente, una vez creado con el prompt correcto:
Eres un experto en el boe, y en notificaciones publicas, debes responder con toda la informaciñón que haya disponible. (Como ejemplo)
Debemos añadir una fuente de conocimiento, en este caso, Busqueda en Azure AI:
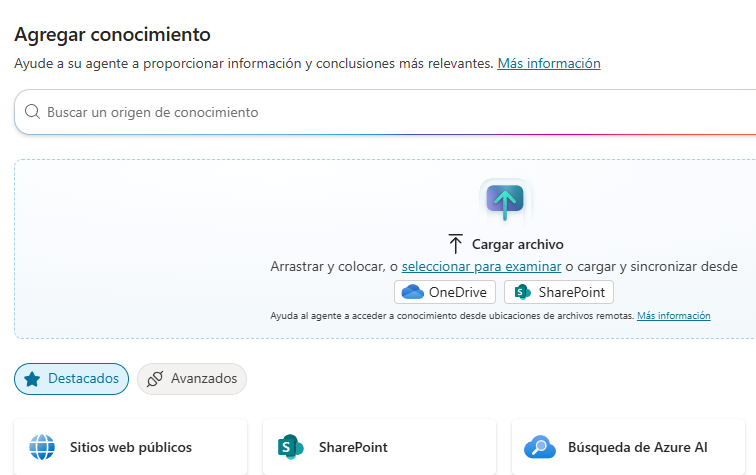
Donde pondremos el endpoint y la key de nuestro recurso de Azure Search.
Pruebas
Llegados a este punto, ya podríamos realizar preguntas a nuestro agente sobre el BOE, pero ojo: solo hemos indexado un documento de pruebas, aquel que subimos desde el Blob Storage para que nos permitiera crear de manera correcta los skills.
Ahora es el momento de popular dicho índice, de darle más contenido, y esto lo hacemos de la siguiente manera: lo primero, debemos consultar las propiedades de nuestro índice.
{
"@search.score": 0.8085195,
"chunk_id": "BOE-A-2025-24764_pdf_3",
"parent_id": "BOE-A-2025-24764_pdf",
"chunk": " - ISSN: 0212-033X\n",
"title": "BOE-A-2025-24764_pdf",
"text_vector": [
-0.010150857,
0.0060054627,
¿Donde esta la magia de Python?
La magia está que ahora podremos desde nuestro código de Python, con toda la arquitectura creada, hacer lo siguiente:
- Buscar todos los enlaces con documentos pdfs que existan en la web
- Extraer su contenido en bruto
- Dividir su contenido en 8000 caracteres (para no estresar al modelo)
- Con todos esos trozos o chunks, y he aquí lo nuevo, haremos lo siguiente:
def split_text(text, max_chars=8000):
return [text[i:i+max_chars] for i in range(0, len(text), max_chars)]
chunks = split_text(full_text)
total_chunks += len(chunks)
for i, chunk in enumerate(chunks):
if chunk.strip():
try:
embedding = openai_client.embeddings.create(
input=chunk,
model=openai_deployment
)
vector = embedding.data[0].embedding
raw_id = link.split("/")[-1]
clean_id = re.sub(r'[^a-zA-Z0-9_-]', '_', raw_id)
documento = {
"chunk_id": f"{clean_id}_{i}",
"parent_id": f"{clean_id}",
"chunk": chunk,
"title": f"{clean_id}",
"text_vector": vector
}
documentos.append(documento)
except Exception as e:
print(f"❌ Error al generar embedding para fragmento {i}: {e}")
except Exception as e:
print(f"❌ Error al procesar PDF {link}: {e}")
Con cada trozo llamaremos, desde Python, al modelo Ada, pasando el chunk para que nos devuelva su equivalente vectorial (embedding). Montaremos el modelo (similar al que ya existe en el índice) y lo enviaremos a Azure Search.
Es decir, generaremos contenido en el índice desde Python, de modo que, usando un job, una Azure Container Instance o una Function, programadas una vez al día, seremos capaces de descargar el contenido del BOE del día, trocearlo, obtener su representación vectorial y enviarlo al indexador para su posterior procesamiento en Copilot Studio, quedando de la siguiente manera:
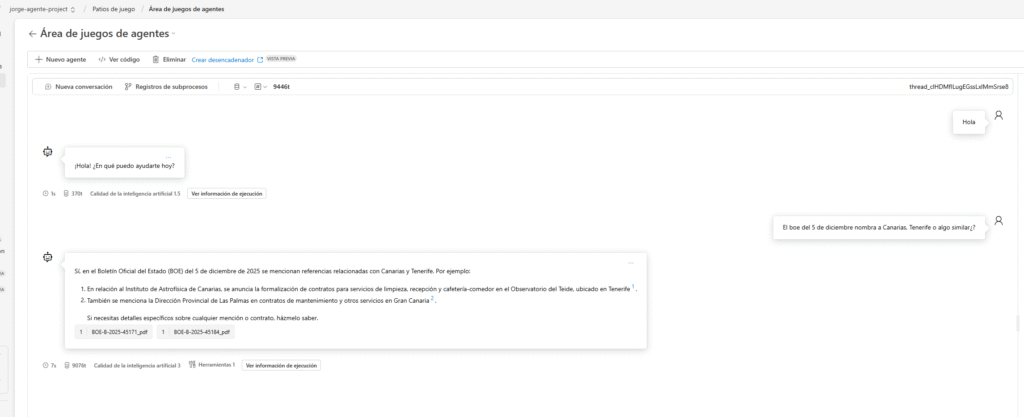
Con esto tendremos nuestro Scraping del BOE listo y dispuesto para que cada día tengamos la última información del mismo a toque de nuestros dispositivos.
Os comparto el código https://github.com/jorgefdezsa/BoeScrapping
GRACIAS
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.